For source files SHA1 are calculated excluding newlines, tabs, whitespace.
The reason behind this is SHA1 takes into account all the above mentioned factors and then calculates the SHA1. This can cause issue / confusion for detection purpose
For example:
If company X and company Y both use the SHA1 file names ‘jpc_t1cod.h’, technically they are same and the SHA1 should be same. Now , if company X source file has extra whitespace or tabs due to manual error, the SHA1 for company X will be different from company Y inspite the fact they are using the same source file
Manual way of calculating SHA1:
-
Install Notepad ++ and 7Zip
-
Open the source file
-
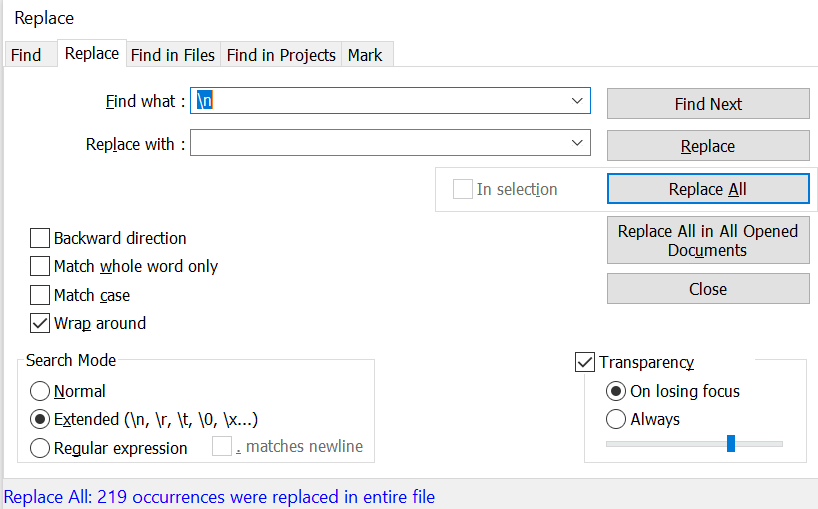
Press Ctrl + F → Go to ‘Replace’ tab
-
Check ‘Wrap around’ and uncheck any other boxes if checked
-
Now type \n in the Find What and leave Replace with empty
-
Type \r in the Find What and leave Replace with empty
-
Type \t in the Find What and leave Replace with empty
-
Press Space bar once in the Find What and leave Replace with empty
-
Save the file as copy
-
Now navigate to the file → Right-click → Click CRC SHA → Click SHA1